腾讯音乐4.29 客户端开发面经
面试流程:
- 面试官介绍部门情况
- 自我介绍(面试官要求介绍项目什么的)
- 问答环节
问题:
tcp建立连接是3次握手,断开连接是4次挥手,为什么会有这个差异?
断开连接为什么要4次,而不是3次?
- TCP连接为什么要三次握手?
- 原因:
- 客户端发出SYN,并收到ACK,这就是两次网络传输了。
- 同样服务器端也发出SYN,且等待对方回复,这也是两次网络传输。
- 加起来难道不是四次吗?实际上服务器端将对客户端 SYN(1) 的回复和自己 SYN(1) 的请求合并了,所以建立一个 TCP 连接最少只需要经过三次网络传输
- 举例:已失效的连接请求报文
- 原因:
- TCP断开连接为什么需要四次挥手?
- 原因:
- 发起断开方发出FIN,并收到ACK,这就是两次网络传输了。
- 同样被断开方也发出FIN,且等待对方回复,这也是两次网络传输。
- 为什么服务端返回ACK的时候不一起发送FIN?因为在收到FIN时,服务端可能还有数据要发送,等到数据传输完时再发送FIN
- 原因:
ping命令使用过吗?traceroute跟它其实差不多,但是那个traceroute为什么能够探索到服务器的各个节点。
traceroute是linux/unix系统中用于分析本地到目标网络地址间的路由转发路径的工具,也常用于诊断网络链路不通或异常的发生位置。windows下命令为tracert www.baidu.com
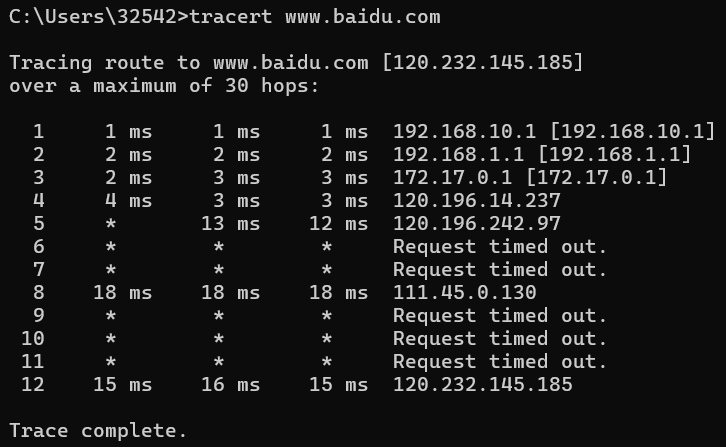
- 每一跳的IP和时延信息是怎么得到的?
- 为什么每一跳有3个时延信息,有时还会显示2个或者3个IP地址?
- 为什么有些跳数显示的结果是请求超时?为什么有节点请求超时了还能到达后续的节点?
traceroute/tracert的原理
- 向目标IP发送3个TTL=n(n起始值为1)的ICMP ping request报文,等待回应
- 如果收到
ICMP ping response报文,则说明路由成功,通过n跳可以到达目标IP,traceroute工作完成。request和response的时间间隔就是时延,由于发送了3个request,因此有3个时延信息。 - 如果收到
ICMP TTL exceeded报文,则说明第n跳路由到达了这个报文的发送节点。IP报文的TTL字段每经过一次路由转发就会减1,当减到0时当前的转发节点就会向报文的源IP发送一个ICMP TTL exceeded报文,因此发送了这个报文的节点就是第n跳的路由节点。由于发送了3个request,因此会返回3个报文和对应的时延信息。由于到目标IP的路由路径不一定是唯一的,因此报文在第n跳时到达的节点不一定是同一个,就有可能会输出多个第n跳节点地址。 - 如果在request发出3秒(默认超时时间)后仍然没有收到任何回应,则这轮检测超时。但这并不意味着目标IP不可达,而很可能是因为第n跳到达的节点不允许发送TTL exceeded报文。因此traceroute会继续后面的探测过程。
- 将TTL加1,回到第1步继续探测。
为什么https比http更安全?答:因为https在http的基础上使用了tls协议进行加密。
- 讲一讲整个加密过程
- 所以密钥本身是对称加密的,还是那个非对称加密?
tcp三次握手成功以后,比方说给对方发1k的数据,对方会有什么下一步的动作?
tcp报文头多少字节 20~60B
udp报文头部为8B
stl的vector是线程安全的吗?
是,所有操作加了同步锁,不支持多线程操作
vector特点:
1.动态分配空间,当空间不足时,会执行分配新空间——复制元素——释放原空间;
2.在末端插入和删除执行效率高,在其他位置插入和删除效率低(为保持原有相对次序,插入和删除点之后的元素需要整体后移);
3.删除数据并不会释放已分配的空间,因此vector的capacity(容量)大于vector的size(元素个数);
4.支持随机访问,且执行效率高;
5.vector是线程安全的,所有操作加了同步锁,不支持多线程操作
#vector跟数组的差别
区别
1.大小固定 vs 大小可变:数组是一个具有固定大小的连续内存块,一旦定义后,其大小无法改变。
vector是一个动态数组,它使用了自动扩容机制,可以根据需要动态调整大小。可以通过添加或删除元素来改变vector的大小。
2.初始化:数组的大小在定义时必须确定,并且可以使用初始化列表或循环初始化等方式进行初始化。
vector的大小可以在定义时指定,也可以在后续使用push_back()、emplace_back()等函数插入元素进行初始化。
3.访问元素:数组通过索引直接访问元素,可以使用下标运算符[]或指针运算符*来访问特定位置的元素。
vector也可以使用下标运算符[]访问元素,还可以使用at()函数进行边界检查。
4.自动内存管理:数组需要手动管理内存,包括分配和释放内存。
vector自动处理内存管理,会自动增加或减少内存以适应元素的数量。
5.功能差异:vector提供了许多方便的成员函数,如push_back()、pop_back()、insert()、erase()等,用于在尾部或指定位置添加、删除元素。
数组本身没有提供这些功能,需要手动编写代码来实现。
map底层的红黑树的实现原理
C++虚函数跟普通的函数有什么区别吗?
虚函数表是在什么阶段,可以知道它自己的指针是多少。
utf16,包括utf32,讲一下他们的差异。
utf8
特点:使用变长字节数
原因:可以理解为按需分配,节省存储空间
优势:节省空间;劣势:不利于程序内部处理
而UTF-32这样等长码元序列(即等宽码元序列)的编码方式就比较适合程序处理,当然,缺点是比较耗费存储空间
编码方式:最短为一个字节,通过utf8首字节就能判断编码有几个字节
- 如果首字节以0开头,肯定是单字节编码(即单个单字节码元);
- 如果首字节以110开头,肯定是双字节编码(即由两个单字节码元所组成的双码元序列);
- 如果首字节以1110开头,肯定是三字节编码(即由三个单字节码元所组成的三码元序列),以此类推。
这里的0相当于终结标志
前缀码的作用:区分和标识
除了单字节编码外,由多个单字节码元所组成的多字节编码其首字节以外的后续字节均以10开头(以区别于单字节编码以及多字节编码的首字节)。
utf16
特点:2字节或者4字节(没有办法兼容ASCII编码,ASCII编码使用1 Byte来进行存储)
字节顺序问题:如某字符为十六进制编码
4E59,按两个字节拆分为4E和59- 读取顺序 显示字符 Windows 4E 59 奎 Mac 59 4E 乙 引入:字节顺序标记(英语:byte-order mark,BOM)来标记是大端序还是小端序。
BOM:是一个有特殊含义的统一码字符,码点为
U+FEFF。当以UTF-16或UTF-32来将UCS/统一码字符所组成的字符串编码时,这个字符被用来标示其字节序。字符
U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序,是高位在前还是低位在前。
空的class大小是多少?
- 空类大小=1,因为编译器需要安插进去一个
char,使得这个 class 对象得以在内存中被配置独一无二的地址。 - 某个类A继承该空类
- 如果A为空,
sizeof(A)=1 - 如果A不为空,
sizeof(A)=真实大小
- 如果A为空,
- 如果一个类没有成员变量,但是含虚函数/虚继承别的类,则会生成一个
vptr,sizeof(A)=4/8
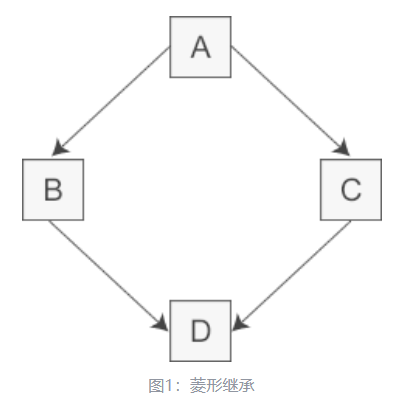
虚继承
多继承:多个直接基类中产生派生类,存在问题:多个基类相互交织
假如类 A 有一个成员变量 a,那么在类 D 中直接访问 a 就会产生歧义,编译器不知道它究竟来自 A –>B–>D 这条路径,还是来自 A–>C–>D 这条路径。
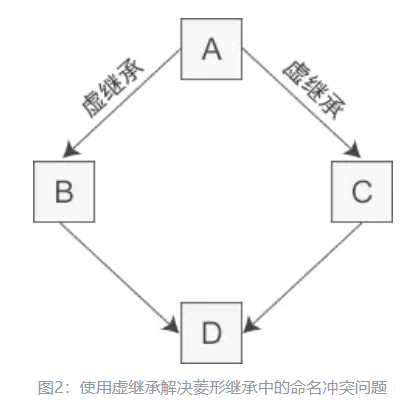
虚继承:为了解决多继承时的命名冲突和冗余数据问题,C++ 提出了虚继承,使得在派生类中只保留一份间接基类的成员。
目的:让某个类做出声明,承诺愿意共享它的基类。
本例中的 A 就是一个虚基类。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含一份虚基类的成员。
计算类的大小,还要考虑字节对齐
定义一个结构体,里面可能有很多的数据类型。在不同的编译器,不同的系统下,结构体大小可能会有不同的大小。你觉得是因为什么?(字节对齐)
- 内存对齐(Padding):
为了提高数据访问的效率,许多处理器和编译器会要求数据按照特定的边界对齐,不同的编译器可能会有不同的默认对齐设置或对齐策略。例如,某些处理器可能要求一个int类型的变量在4字节边界上对齐。如果结构体中的某个成员不满足这个对齐要求,编译器会在成员之间插入额外的空间(填充字节),以达到所需的对齐。这会导致结构体的大小在不同系统或编译器下有所不同。 - 数据类型的大小:
虽然标准数据类型(如int、long等)在大多数系统上都有固定的大小,但在某些系统或编译器下,它们的大小可能会有所不同。
C++的加锁方式
C++子类跟基类的构造顺序和析构顺序,为什么?
局部变量在进程内存的哪一块里面
一般全局变量存放在数据区,局部变量存放在栈区,
动态变量存放在堆区,函数代码放在代码区。
函数的参数的压栈顺序:参数从右到左入栈
例:void func(int a,int b,int c),进栈顺序为:c b a.