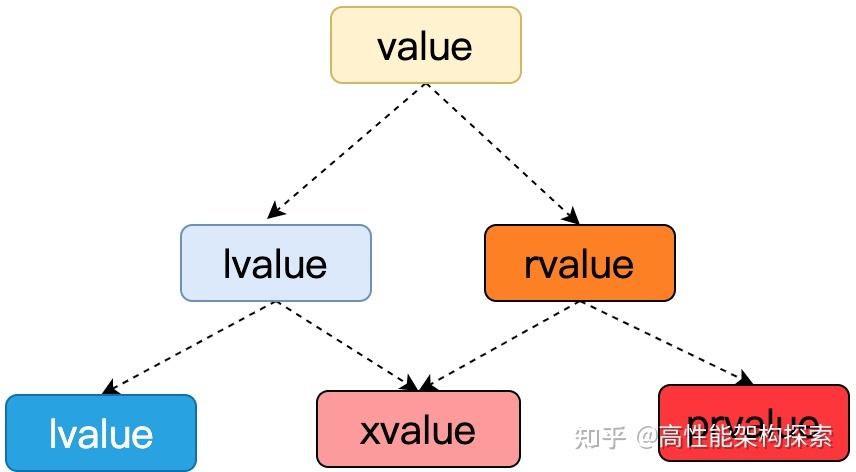
容器和类容器
string
1.string不是容器,但是有跟序列容器类似的成员函数
begin和endemptysizeswap(支持交换)- 支持
==、<等比较运算
2.string的内存布局
| h | e | l | l | o | ! | \0 |
|---|---|---|---|---|---|---|
begin |
end |
|||||
front |
back |
begin和end是迭代器,类似于指针,end指向末尾+1front和back是引用
3.string其他用法
size()的复杂度是O(1),strlen()的复杂度是O(N)- 支持字符串的拼接和查找
nops是一个string的常数,当查找不存在的字符时会返回nops- 支持到数字的互转:
stoi()和to_string
序列容器
array
array的特点:
和C数组一样在栈上分配,性能方面没有差异
需要编译期确定数组大小
提供了
begin、end、size等通用成员函数解决了C数组的怪异行为
不能按值拷贝,具体表现:
a. 直接赋值:在C中,不能直接将一个数组赋值给另一个数组,
int a[5] = {1, 2, 3, 4, 5}; int b[5]; b = a;是非法的,array<int, 5> a = {1, 2, 3, 4, 5}; array<int, 5> b; b = a;是合法的b. 函数传参:数组作为函数参数,实际上传递的是指向数组的指针,而不是整个数组的拷贝
作为参数有退化行为,被调用函数不能获得C数组的长度
支持
==<等比较运算(原生数组不能直接使用比较运算符,此时比较的是两个数组的地址,array、vector会自动逐元素比较数组)
vector
- 最常用的序列容器
- 大小可变的动态数组
- 为尾部增删元素而优化
vector的内存布局
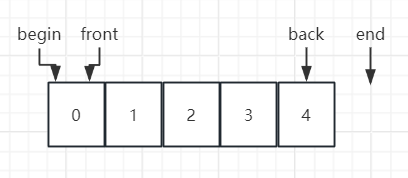
- begin、end:指针、迭代器
- front、back:引用
异常安全要求
当 vector 空间不够时,扩容时希望在内存重分配时使用元素的移动构造函数的话,必须声明为 noexcept
否则容器会使用拷贝构造函数
原因:保证强异常安全性,在 vector的 insert、push_back等操作中保证强异常安全性,怎么实现:如果插入的时候空间不够会扩容,在新的内存块中相应的位置构造要求插入的成员,如果失败的话,抛异常并释放内存,如果成功的话,将原先的内存拷贝或者移动过去。如果在移动过程中出现异常,新的内存块没构造完成,旧的内存块被移走,就没办法保证强安全性。 vector保证强异常安全性是指:如果操作失败,能够保证完整的回退到当前插入操作之前的状态。
示例程序:
1 | class Obj1 |
1 | Obj1() |
运行结果:Obj1扩容使用拷贝构造,Obj2扩容使用移动构造
deque
- 双端队列
- 为头尾高效增删元素而优化
deque的内存布局
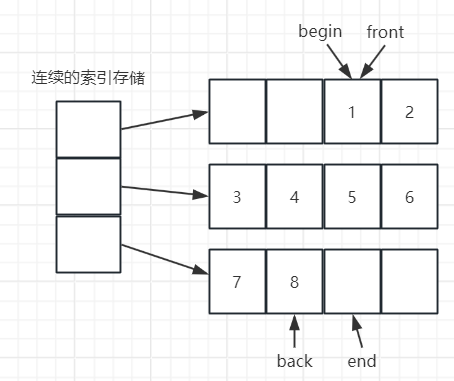
跟 vector 相比的优点:头尾插入的时候不会涉及额外的移动操作,只需要创建一个新的内存块,只有当索引存储不够时才需要移动索引存储,所以当需要在头尾频繁插入数据时,deque是一个性能很高的选择
deque的特点
- 只从头尾进行增删时,容器里的对象永远不需要移动
- 容器里的元素只是部分连续
- 元素的存储大部分仍然连续,遍历性能较高
- 支持使用下标访问容器元素,仍能保持O(1)
list
- 双向链表
- 为任意位置插入和删除优化
list内存布局:同理,begin和front指向首,back指向尾,end指向尾+1
list的特点
- 提供高效的、O(1)复杂度的任意位置的插入和删除操作
- 不支持使用下标访问元素
- 不支持
sort算法,但能使用其成员函数sort,例:sort(list.begin(),list.end())错误,正确:list.sort()
forward_list
- 单向链表
- 比
list少了前继结点,比list内存占用少
容器适配器
queue
- 先进先出的容器适配器
- 底层默认使用
deque,也可以是list - 不能按下标访问,只能从首部弹出,尾部添加
stack
- 后进先出的容器适配器
- 底层默认使用
deque,也可以是list、vector
priority_queue
优先级队列(部分排序的队列),排序的部分在顶部
默认使用
less排序排序的末项在顶部,默认是大根堆
模板参数: _Tp – Type of element. _Sequence – Type of underlying sequence, defaults to vector<_Tp>. _Compare – Comparison function object type, defaults to less<_Sequence::value_type>. priority_queue<int,vector<int>,my_greater> que; // 函数 "my_greater" 不是类型名C/C++(757) // 所以这里的参数也只能是函数对象1
2
3
4
5
6
7
8
9
10
11
12
------
**函数对象 `less`**
```c++
template <class T>
struct less:binary_function<T,T,bool>{
bool operator()(const T& x,const T& y){
return x<y;
}
}
函数对象:在class或struct中实现 operator() 的对象,生成这样一个对象之后,可以使用 () 来调用函数,行为跟普通函数有点区别
注意:sort可以接受函数指针作为参数,但是 map set只能接受函数对象
1 | bool my_greater(int x, int y) |
关联容器
- 有序的容器,默认使用
less set、map、multiset、multimap:key是否可重复- 查找、插入和删除的时间复杂度都是
O(log N)
无序关联容器
容器元素间没有顺序关系
默认使用
hash,也可以使用自定义的函数对象1
2
3
4
5
6
7template<typename T>
struct hash<complex<T>>{
size_t operator()(const complex<T> &v)const noexcept{
hash<T> h;
return h(v.real())+h(v.imag());
}
};unordered_set、unordered_map、unordered_multiset、unordered_multimap:key是否可重复