1.什么是const
const是C/C++中的关键字,一般用来定义一个常量,所以const修饰的变量不能修改它的值

2.什么是#define
#define是一条预编译指令,编译器在编译阶段会将所有使用到#define的地方进行替换
1 |
|
文件系统是操作系统中负责把用户的文件存到磁盘硬件中
基本数据单位:文件
“万物皆文件”
为每个文件分配两个数据结构
索引节点inode
记录:文件的元信息
inode编号、文件大小、访问权限、创建/修改时间
数据在磁盘中的位置
索引节点是文件的唯一标识
目录项dentry
记录:文件的名字、索引节点指针、与其他目录项的层级关联关系
不只是表示目录
也可以表示文件
目录项是由内核维护的一个数据结构
目录也是文件
普通文件保存文件数据
目录文件保存子目录或者文件
目录项vs目录
区别
目录是文件,存放在硬盘里
目录项是内核的一个数据结构,缓存在内存中
关系
查询目录频繁从磁盘读,效率低
内核把读过的目录用目录项这个数据结构缓存在内存中
关系
目录项和索引节点是多对一的关系
区别
索引节点存放在硬盘
目录项存放在内存
文件数据如何存储在磁盘
逻辑块/数据块
磁盘读写的最小单位是扇区(512B),读写效率低
文件系统把多个扇区组成了一个数据块
每次读写的最小单位就是逻辑块
linux中逻辑块大小为4KB(一次性读写8个扇区)
加速文件访问:把索引节点加载到内存
磁盘格式化后的存储区域
超级块
索引节点区
数据块区
加载策略:只有需要的时候加载进内存
超级块:文件系统挂载时加载进内存
索引节点区:当文件被访问时加载进内存
断开连接为什么要4次,而不是3次?
traceroute是linux/unix系统中用于分析本地到目标网络地址间的路由转发路径的工具,也常用于诊断网络链路不通或异常的发生位置。windows下命令为tracert www.baidu.com
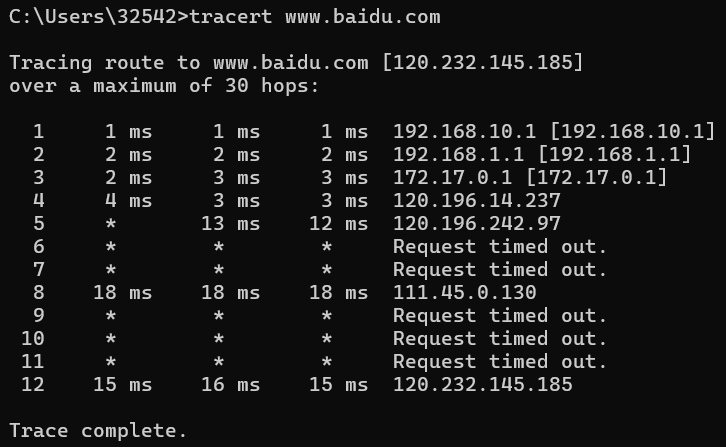
- 每一跳的IP和时延信息是怎么得到的?
- 为什么每一跳有3个时延信息,有时还会显示2个或者3个IP地址?
- 为什么有些跳数显示的结果是请求超时?为什么有节点请求超时了还能到达后续的节点?
traceroute/tracert的原理
ICMP ping response报文,则说明路由成功,通过n跳可以到达目标IP,traceroute工作完成。request和response的时间间隔就是时延,由于发送了3个request,因此有3个时延信息。ICMP TTL exceeded报文,则说明第n跳路由到达了这个报文的发送节点。IP报文的TTL字段每经过一次路由转发就会减1,当减到0时当前的转发节点就会向报文的源IP发送一个ICMP TTL exceeded报文,因此发送了这个报文的节点就是第n跳的路由节点。由于发送了3个request,因此会返回3个报文和对应的时延信息。由于到目标IP的路由路径不一定是唯一的,因此报文在第n跳时到达的节点不一定是同一个,就有可能会输出多个第n跳节点地址。udp报文头部为8B
是,所有操作加了同步锁,不支持多线程操作
vector特点:
1.动态分配空间,当空间不足时,会执行分配新空间——复制元素——释放原空间;
2.在末端插入和删除执行效率高,在其他位置插入和删除效率低(为保持原有相对次序,插入和删除点之后的元素需要整体后移);
3.删除数据并不会释放已分配的空间,因此vector的capacity(容量)大于vector的size(元素个数);
4.支持随机访问,且执行效率高;
5.vector是线程安全的,所有操作加了同步锁,不支持多线程操作
#vector跟数组的差别
区别
1.大小固定 vs 大小可变:数组是一个具有固定大小的连续内存块,一旦定义后,其大小无法改变。
vector是一个动态数组,它使用了自动扩容机制,可以根据需要动态调整大小。可以通过添加或删除元素来改变vector的大小。
2.初始化:数组的大小在定义时必须确定,并且可以使用初始化列表或循环初始化等方式进行初始化。
vector的大小可以在定义时指定,也可以在后续使用push_back()、emplace_back()等函数插入元素进行初始化。
3.访问元素:数组通过索引直接访问元素,可以使用下标运算符[]或指针运算符*来访问特定位置的元素。
vector也可以使用下标运算符[]访问元素,还可以使用at()函数进行边界检查。
4.自动内存管理:数组需要手动管理内存,包括分配和释放内存。
vector自动处理内存管理,会自动增加或减少内存以适应元素的数量。
5.功能差异:vector提供了许多方便的成员函数,如push_back()、pop_back()、insert()、erase()等,用于在尾部或指定位置添加、删除元素。
数组本身没有提供这些功能,需要手动编写代码来实现。
utf8
特点:使用变长字节数
原因:可以理解为按需分配,节省存储空间
优势:节省空间;劣势:不利于程序内部处理
而UTF-32这样等长码元序列(即等宽码元序列)的编码方式就比较适合程序处理,当然,缺点是比较耗费存储空间
编码方式:最短为一个字节,通过utf8首字节就能判断编码有几个字节
这里的0相当于终结标志
前缀码的作用:区分和标识
除了单字节编码外,由多个单字节码元所组成的多字节编码其首字节以外的后续字节均以10开头(以区别于单字节编码以及多字节编码的首字节)。
utf16
特点:2字节或者4字节(没有办法兼容ASCII编码,ASCII编码使用1 Byte来进行存储)
字节顺序问题:如某字符为十六进制编码4E59,按两个字节拆分为4E和59
| - | 读取顺序 | 显示字符 |
|---|---|---|
| Windows | 4E 59 | 奎 |
| Mac | 59 4E | 乙 |
引入:字节顺序标记(英语:byte-order mark,BOM)来标记是大端序还是小端序。
BOM:是一个有特殊含义的统一码字符,码点为U+FEFF。当以UTF-16或UTF-32来将UCS/统一码字符所组成的字符串编码时,这个字符被用来标示其字节序。
字符U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序,是高位在前还是低位在前。
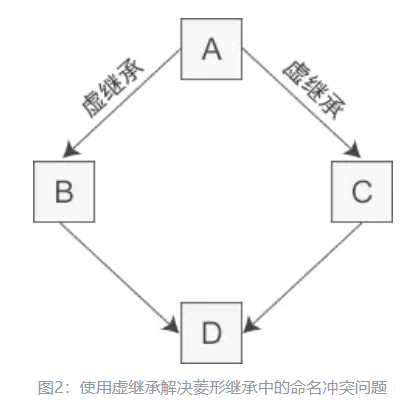
char,使得这个 class 对象得以在内存中被配置独一无二的地址。sizeof(A)=1sizeof(A)=真实大小vptr,sizeof(A)=4/8虚继承
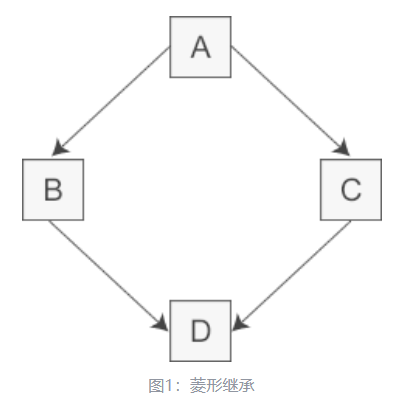
多继承:多个直接基类中产生派生类,存在问题:多个基类相互交织
假如类 A 有一个成员变量 a,那么在类 D 中直接访问 a 就会产生歧义,编译器不知道它究竟来自 A –>B–>D 这条路径,还是来自 A–>C–>D 这条路径。
虚继承:为了解决多继承时的命名冲突和冗余数据问题,C++ 提出了虚继承,使得在派生类中只保留一份间接基类的成员。
目的:让某个类做出声明,承诺愿意共享它的基类。
本例中的 A 就是一个虚基类。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含一份虚基类的成员。
计算类的大小,还要考虑字节对齐
int类型的变量在4字节边界上对齐。如果结构体中的某个成员不满足这个对齐要求,编译器会在成员之间插入额外的空间(填充字节),以达到所需的对齐。这会导致结构体的大小在不同系统或编译器下有所不同。int、long等)在大多数系统上都有固定的大小,但在某些系统或编译器下,它们的大小可能会有所不同。一般全局变量存放在数据区,局部变量存放在栈区,
动态变量存放在堆区,函数代码放在代码区。
例:void func(int a,int b,int c),进栈顺序为:c b a.
Linux内核:宏内核
缺点:系统功能扩展性差,设计之初实现了较多冗余功能,影响操作系统的运行效率和系统稳定性
解决办法:引入内核模块动态加载机制——通过内核模块的扩展和动态加载实现操作系统功能的扩充,当一些内核模块不再使用时可以卸载该模块,以保证操作系统的运行效率和系统稳定性。
Linux内核=基本内核+一系列内核模块
系统启动——加载基本内核——用户按照需要动态加载系统内核模块——不需要时再从内核卸载
好处:a.让内核保持很小的尺寸,同时又非常灵活;b.可以不通过重构内核并频繁重启的方式来尝试运行新内核代码,便于新设备驱动程序的编写和调试
内核模块的加载方式有两种:
insmod命令手工加载模块符号表:所有能够被内核模块使用的资源(基本内核中定义的资源和新加载模块中定义的资源),被操作系统以内核输出符号表的形式统一管理。
内核模块加载过程:
模块A输出的符号被模块B使用,则称模块B依赖于模块A,或者模块A被模块B引用
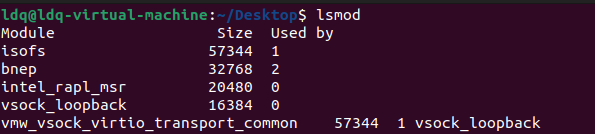
引用计数:新模块加载到内核过程中,内核会检查该模块使用的外部符号,增加这些外部符号所在模块的引用技术。可通过lsmod命令查看系统已加载的内核模块以及模块的引用计数。
内核模块的卸载:通过使用rmmod命令来卸载
内核模块除了可以手动卸载以外,还支持自动卸载——内核模块的自动卸载工作由后台进程kerneld完成,keneld在相应定时器到期时检查,卸载不用的模块
下载地址:http://nodejs.cn/download/

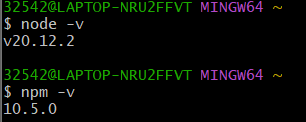
验证是否下载成功
在git bash里面执行下面的命令
1 | node -v |
在git bash里面执行下面的命令
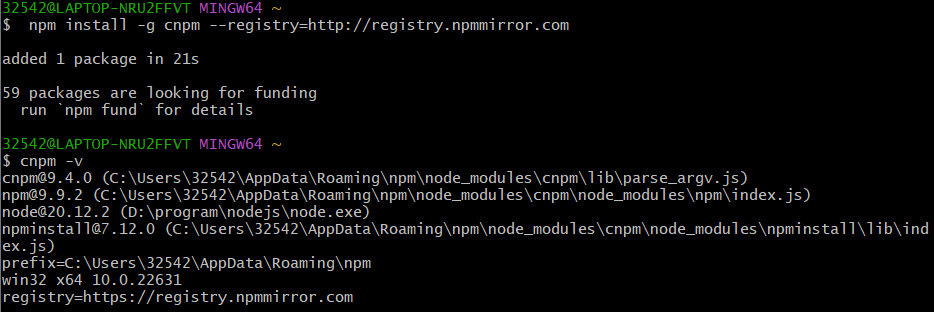
1 | npm install -g cnpm --registry=http://registry.npmmirror.com |
检查是否安装成功
1 | cnpm -v |
在git bash里面执行下面的命令安装hexo
1 | cnpm install hexo-cli -g |
新建或者选择一个文件夹,作为blog文件夹,在该文件夹下打开git bash
然后执行
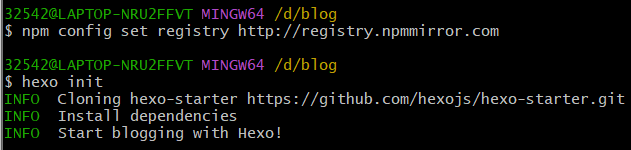
1 | hexo init |
如果跟我一样遇到问题,可以更换淘宝镜像,再执行hexo init
当时输完命令就去吃饭了,具体不知道跑了多久
1 | npm config set registry http://registry.npmmirror.com |
然后执行
1 | cnpm install |
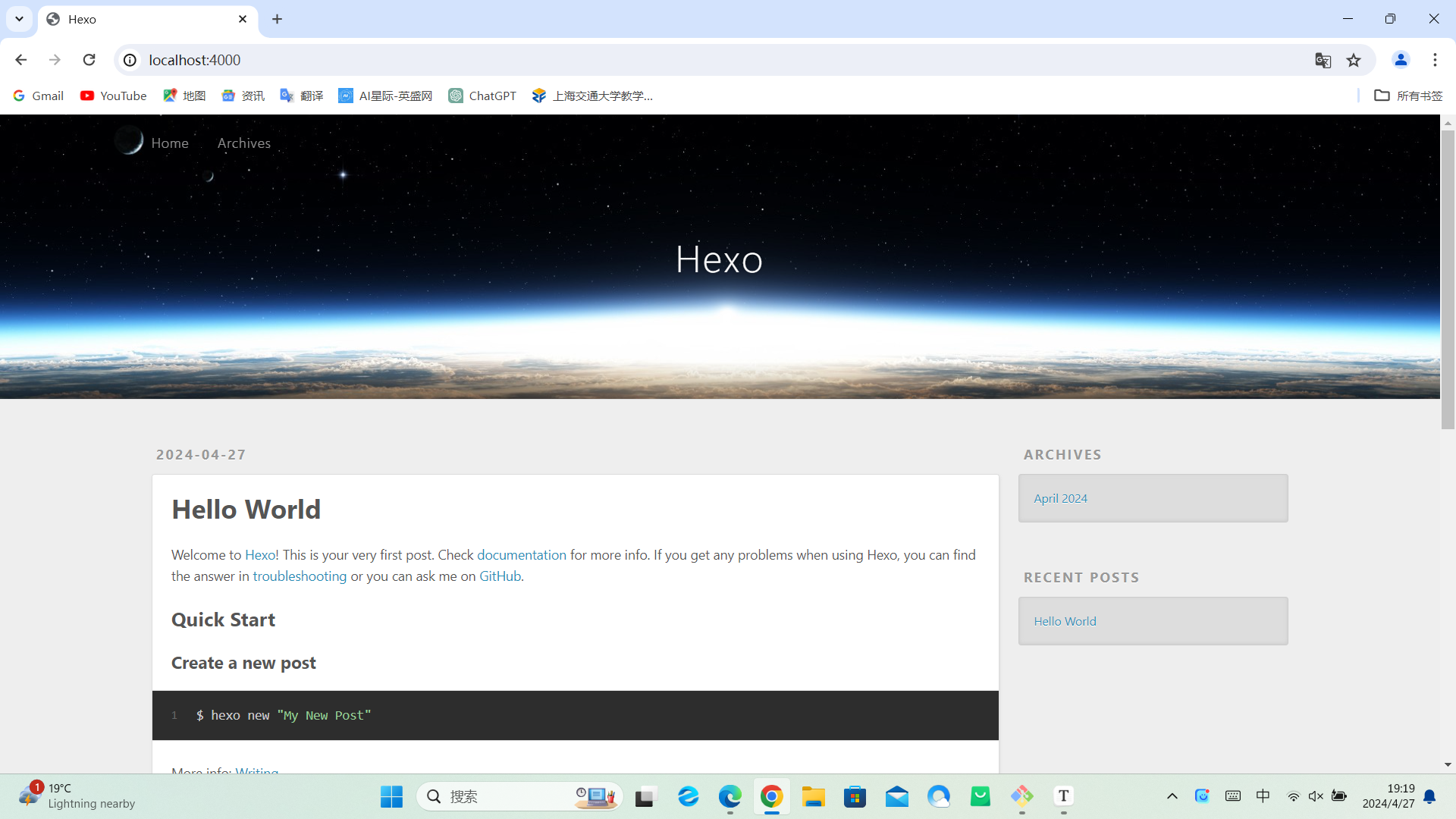
接下来就可以预览博客啦
1 | hexo s |
结果如下,访问这段http开头的网址就可以预览了
注意:不要结束命令或者关闭终端!!!所以复制网址的时候别直接ctrl+C

如果不喜欢默认主题的话,可以更换为next主题(适合新手)
下载主题
1 | git clone https://github.com/theme-next/hexo-theme-next.git themes/next |

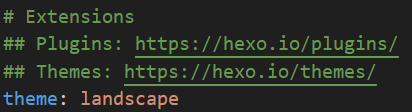
修改配置文件
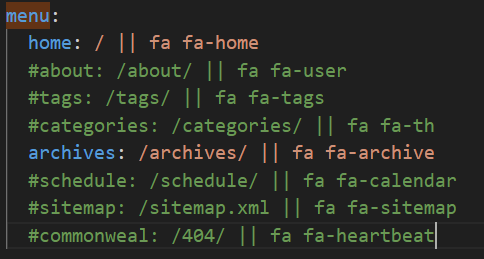
在自定义的博客文件夹下找到_config.yml文件
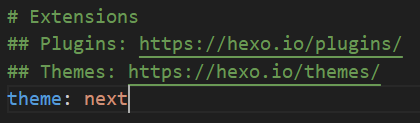
将landscape改为next
预览网站
同样的执行hexo s
注意区分两个文件,名字都为_config.yml
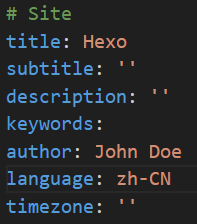
D:\blog\_config.ymlD:\blog\themes\next\_config.yml更改站点配置文件D:\blog\_config.yml,将language改为zh-CN
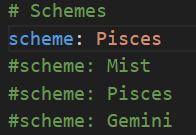
更改主题配置文件D:\blog\themes\next\_config.yml
根据需求更改
你也可以查看文档修改其他值https://hexo.io/docs/configuration.html
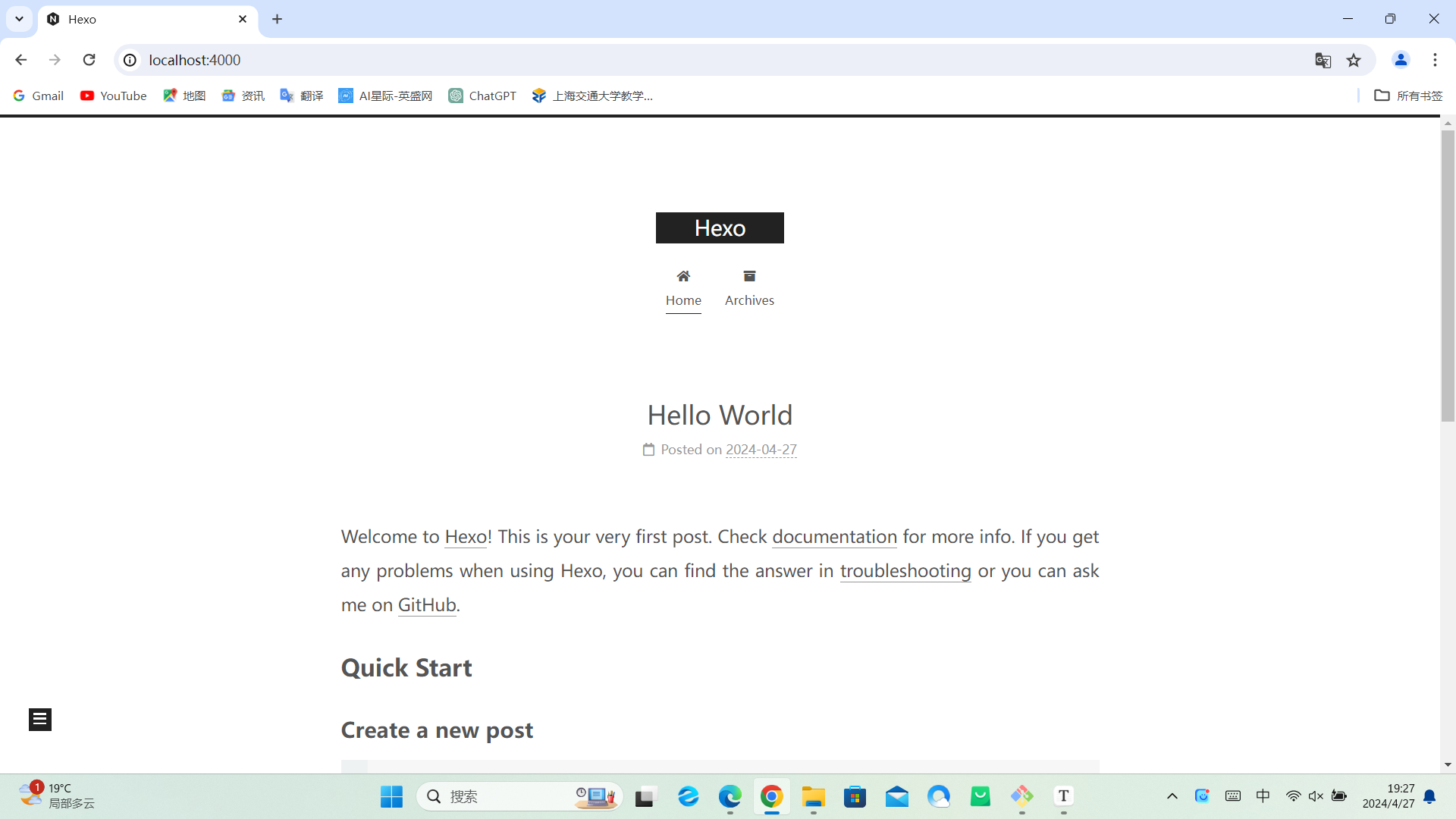
再执行hexo s预览网站,现在网站长这样啦!
如果没有更新的话,可以关掉刚刚git bash的窗口,重新打开就可以看到刷新了
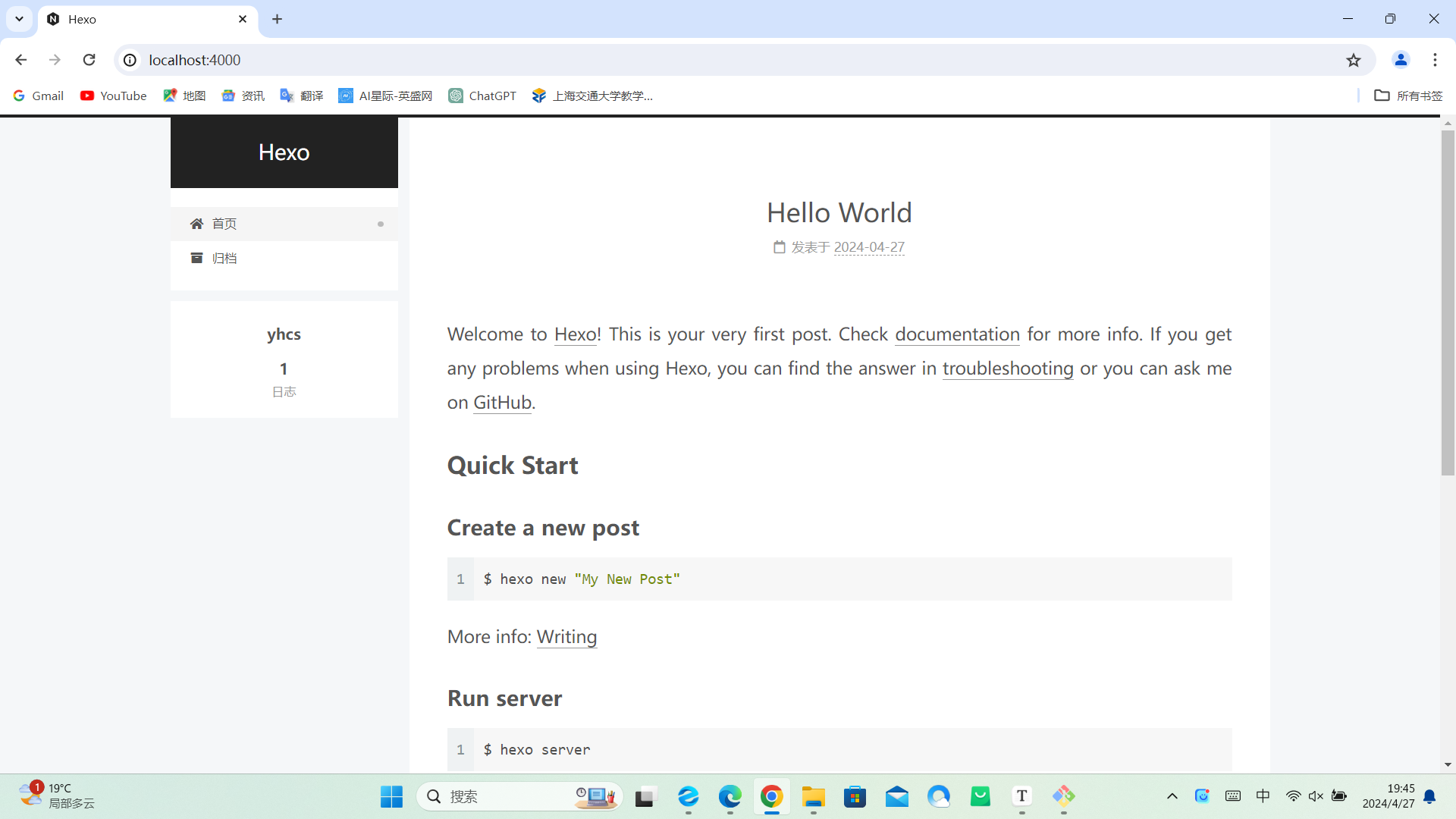
比如,你想创建一个名为“如何使用github搭建个人博客”的文章
在博客根目录下执行
1 | hexo new "How to build a personal blog on GitHub" |

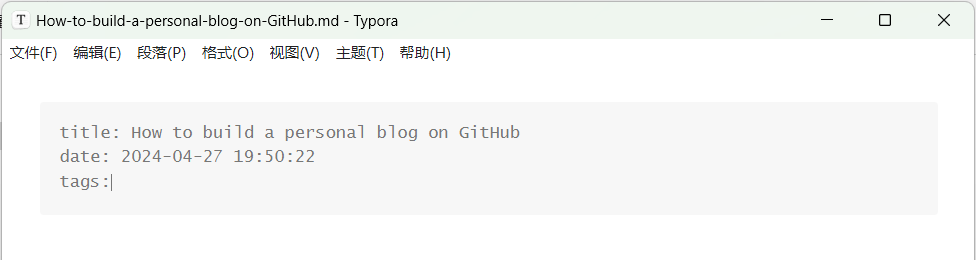
就会生成对应的markdown文件啦
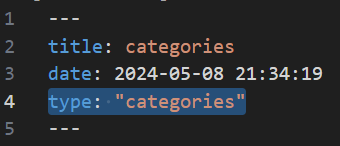
打开文件如下,在这里你可以修改文章标题,在下面输入文章内容
同样的,执行hexo s预览网站
现在只是本地预览,将博客部署到网站上,就可以通过域名访问了
可以通过github部署,也可以通过coding部署
我用的是github
创建一个仓库 Create repository
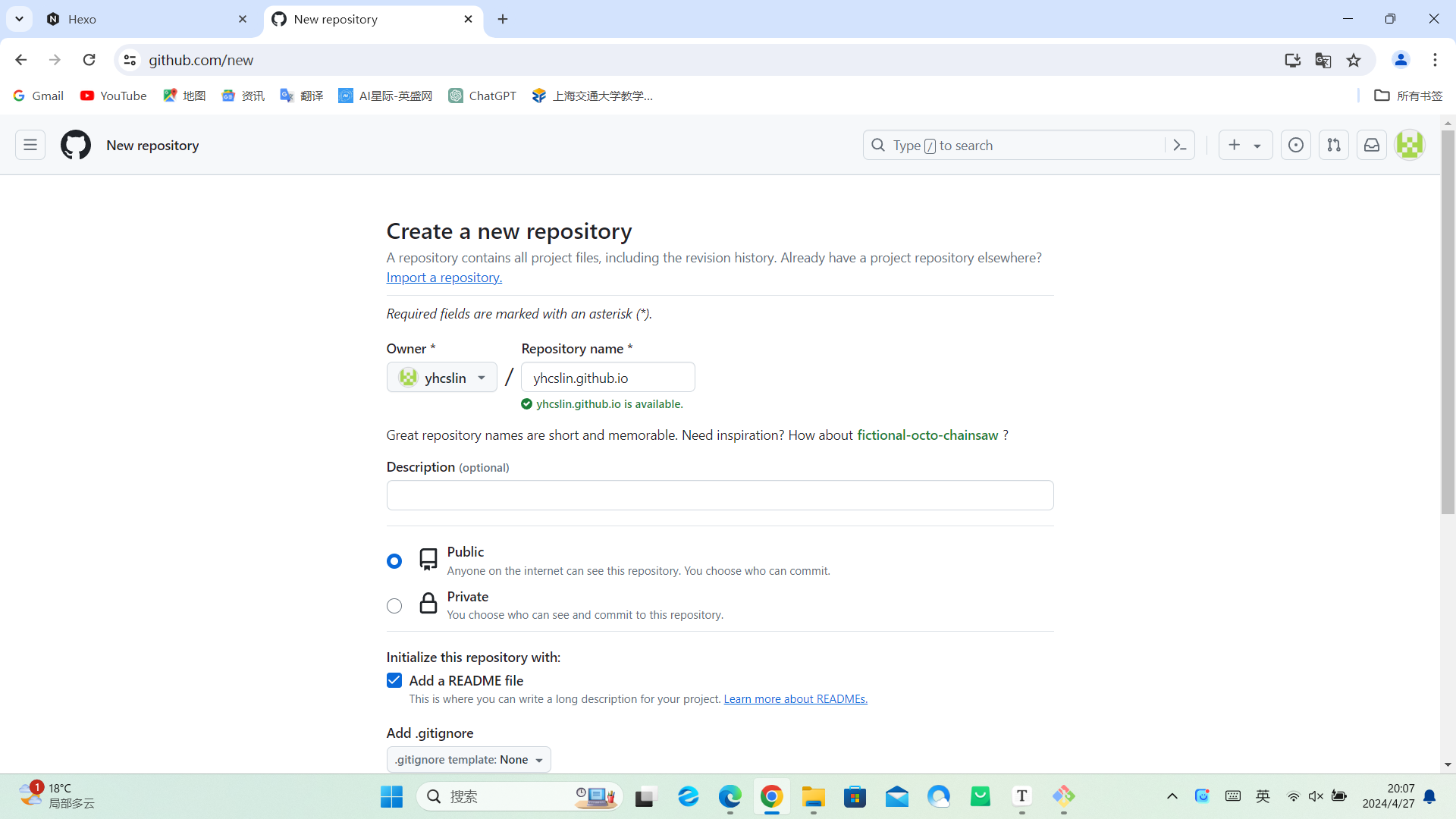
仓库名为用户名+.github.io,勾选初始化README
进行其他配置,创建一个git密钥
1 | ssh-keygen -t rsa -C “your_email@youremail.com“ |
然后执行cat ~/.ssh/id_rsa.pub,复制输出信息
回到github,点击头像,打开Settings,打开SSH and GPG keys,点击new SSH key
在Key那里粘贴密钥,点击Add SSH Key
打开git bash,执行:ssh -T git@github.com,输入yes回车

打开项目,点击Code—SSH,复制地址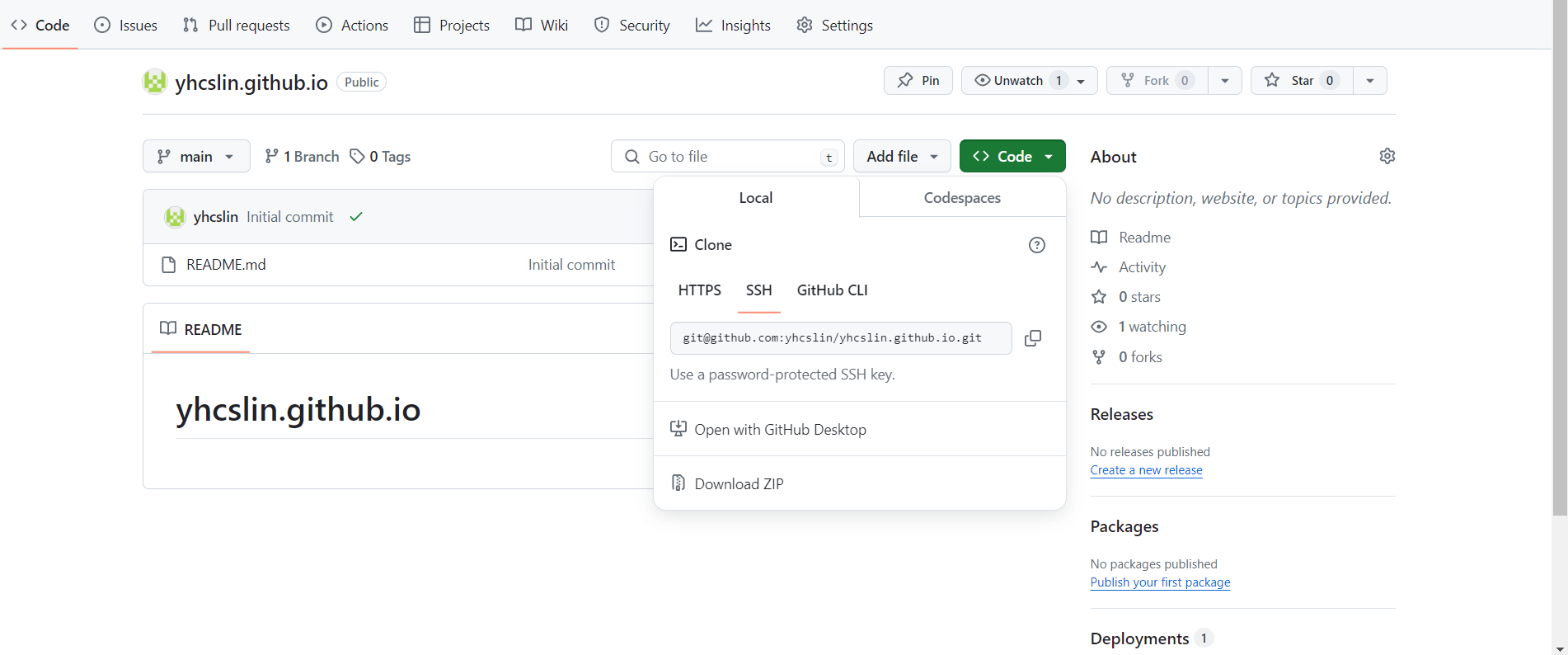
打开站点配置文件
修改
1 | deploy: |
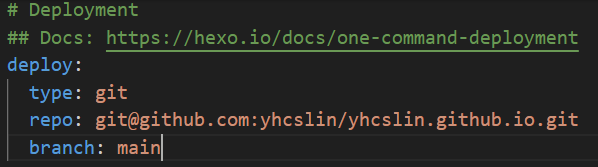
在博客根目录下打开git bash,分别执行下面的命令,更换为你的名字和邮箱
1 | git config --global user.name "yourname" |
安装上传插件
1 | cnpm install hexo-deployer-git --save |
然后执行下面的命令上传
1 | hexo g -d |
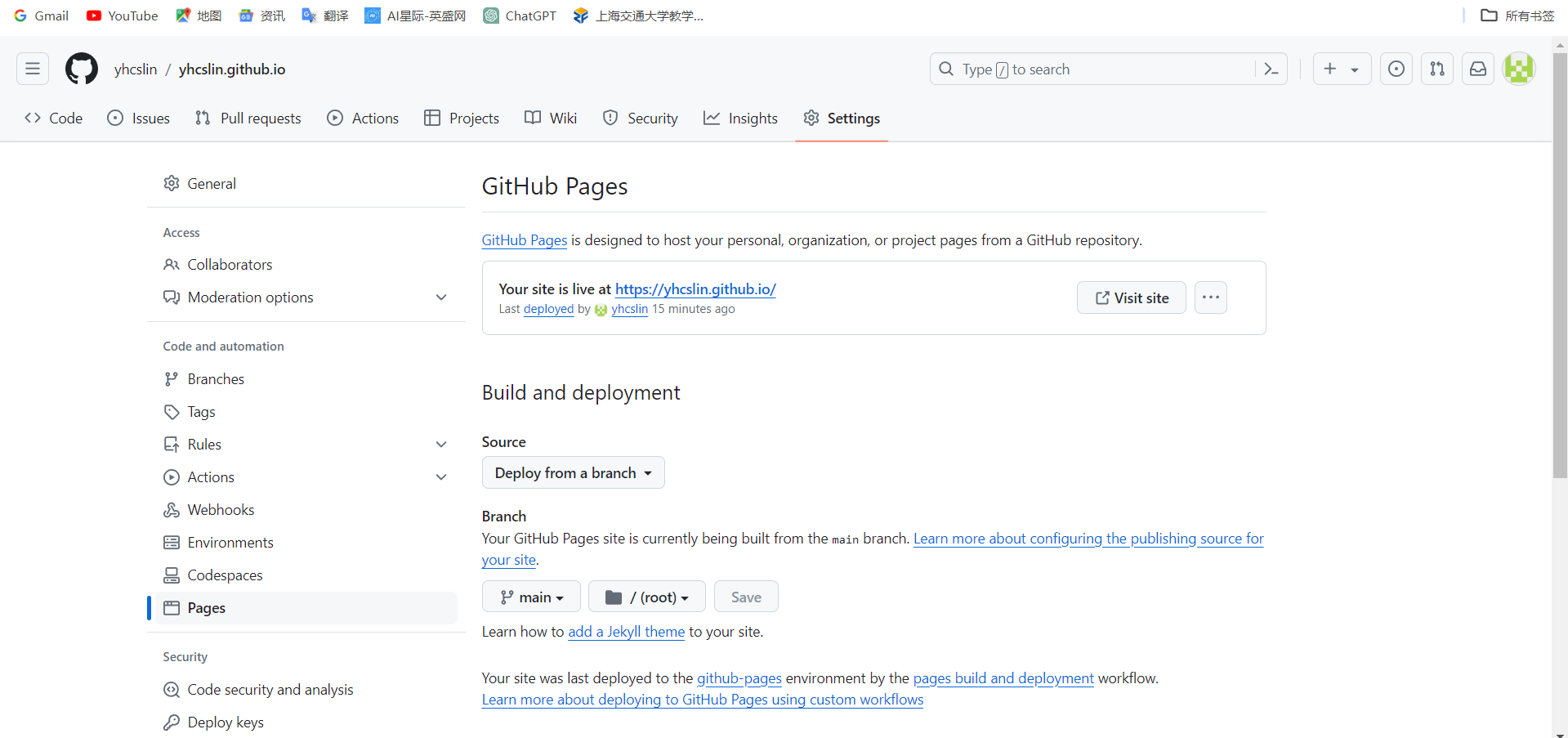
然后打开项目,点击Settings—Pages
出现的就是你的网址
参考链接
- https://www.cnblogs.com/huanhao/p/hexobase.html 比我讲的要详细,但是有些在淘宝镜像那里的链接要更新
- https://cloud.tencent.com/developer/article/2395526 上传图片有问题的可以看这里
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment